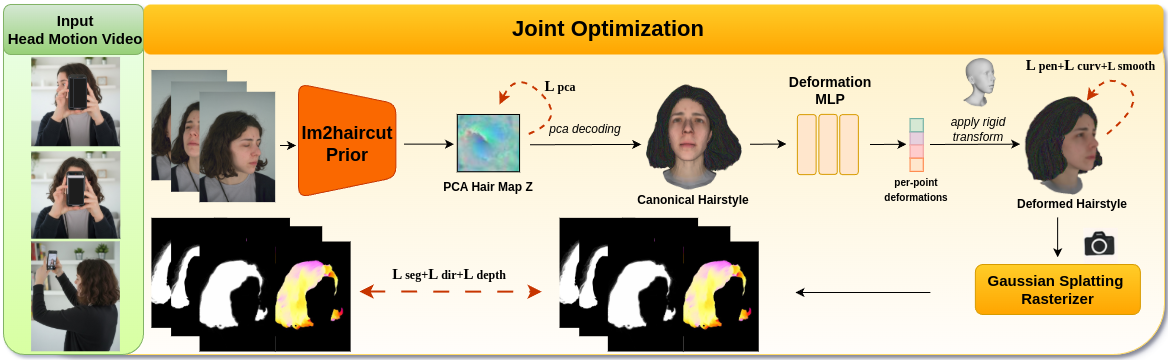
We present Vid2Haircut, a novel approach for strand-based 3D hair reconstruction from monocular head-motion videos. While existing multi-view methods achieve high-fidelity results, they require controlled capture setups. In contrast, single-image approaches suffer from occlusion-driven ambiguities, particularly in unseen regions such as the back of the head. Recent monocular video methods improve reconstruction by leveraging learned priors, but may struggle under natural head motion.
To address this, our approach reconstructs accurate geometry from a short monocular video by leveraging viewpoint variations induced by natural head motion, which help resolve occlusions in poorly observed regions. Specifically, we extend a learned prior for general hair structure by jointly optimizing a shared, scalp-aligned hair map in a canonical space across multiple keyframes. To accommodate hair motion during capture, we incorporate a deformation MLP that predicts residual strand offsets, preventing frame-specific deformations from corrupting the canonical hairstyle.
We further stabilize the reconstruction of weakly observed regions using visibility-aware updates and neighboring-strand smoothness constraints. Experiments on synthetic and real data show that our pipeline improves backside consistency, scalp attachment, and overall 3D reconstruction quality compared to state-of-the-art baselines, while requiring only casual head-motion videos as input.